
Hello! I'm Francesco
Systems, Software & Cloud Engineer
From proof-of-concept to explosive scale, I help you launch faster and stay reliable.
AWS
Terraform
Ansible
Kubernetes
Istio
Linux
Docker
CI/CD
Flux
Argo CD
Actions
CircleCI
Observability
Microservices
Serverless
OIDC
PostgreSQL
Redis
MongoDB
Cassandra
Elasticsearch
RabbitMQ
DuckDB
ClickHouse
LLM
LangChain
Machine Learning
Ruby on Rails
Typescript
Golang
Rust
Python
C++
TailwindCSS
React
Next.js
Remix
Featured projects
Indigo Lighthouse Group
Cloud migration: architected a secure, PCI and HIPAA compliant cloud
infrastructure on AWS, for half the cost and double the performance of
the previous Heroku setup.
Schroders Personal Wealth
End-to-End DevOps: architected and implemented a fully automated CI/CD
pipeline for two mobile apps and a Serverless backend for a high-stakes
finance product, using AWS, Terraform and CircleCI.
Currencycloud (now Visa)
Kubernetes adoption: completely re-architected the
testing and production workflows for a large-scale Ruby and Scala
microservices platform, using Kubernetes, Istio, cutting release
times from hours to seconds.
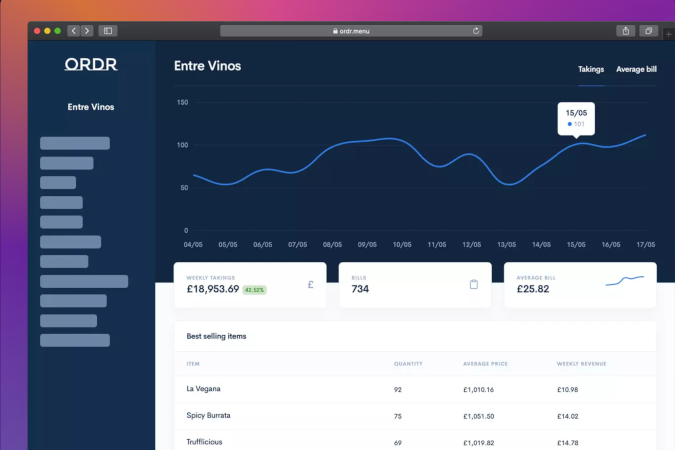
ORDR
Co-founder/CTO: built a comprehensive Restaurant SaaS
platform (Ruby on Rails, Go), including payments, delivery
integrations and advanced order routing algorithms.

Chat with the Law
Side project: a legal chatbot that continuously updates
itself with the latest italian case law, analyzing and summarizing
thousands of documents, using LangChain and OpenAI.
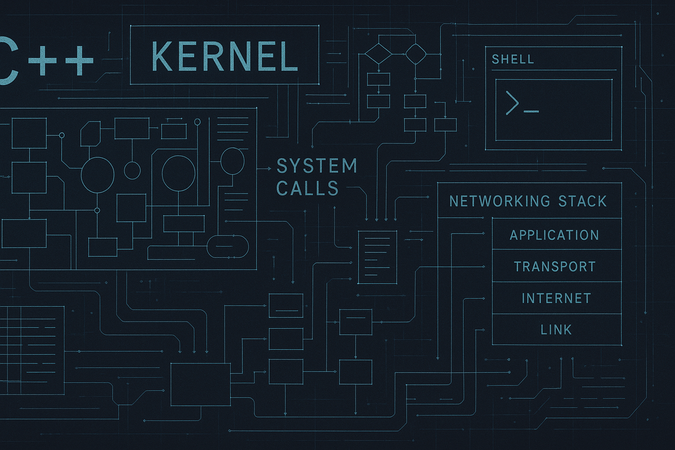
UNIX-like OS
Side project: my first and oldest project, written (and
re-written) in C++, with a custom kernel a fully functional shell and
networking stack. It can compile itself!
I've started tiny and XXL side-projects over the years, and I still do. Check them out!
My story
I've been taking technology apart and rebuilding it since I was 9. What really interests me is understanding why things work the way they do, from large-scale distributed systems right down to the NAND gates.
Now, I apply this foundational understanding to engineer more robust, efficient, and innovative solutions.